어렴풋이 과거엔 프루나, 당나귀부터 최근엔 토렌트로 많이 알려진 파일공유 프로그램들이 있습니다.
이들은 P2P 네트워크 기반으로 동작하는 파일공유방식인데 어떤 원리로 동작하는지 간단하게 알아봅니다.
1. P2P 네트워크?
2. 토렌트
3. P2P네트워크와 HTTP/FTP의 차이점
4. 트래커? DHT?
5. DHT
1. P2P 네트워크
P2P(Peer-To-Peer) 네트워크는 중앙 서버 없이 사용자(피어, Peer)간에 직접 데이터를 공유하는 네트워크 구조를 의미합니다.
일반적인 클라이언트-서버 방식과 달리, 각 사용자가 동시에 클라이언트이자 서버 역할을 수행하는 것이 특징입니다.
P2P 네트워크의 기본 원리
1. 모든 참여자는 동등한 권한을 가짐
일반적인 인터넷 서비스(예: 웹사이트)는 중앙 서버(호스트)에서 데이터를 제공하고, 사용자는 클라이언트로 다운로드하는 방식입니다. 반면, P2P 네트워크에서는 모든 참가자가 데이터를 제공하고 받을 수 있습니다.
2. 분산구조
특정 서버가 다운되더라도 네트워크 전체가 영향을 받지 않습니다.
트래픽 부하가 특정 서버에 집중되지 않고 여러 사용자가 분산해서 감당합니다.
3. 파일 조각화 및 공유
하나의 큰 파일을 작은 조각(Piece) 단위로 나누어 여러 피어(Peer)들에게 공유합니다.
각 피어는 자신이 가진 조각을 다른 피어들에게 제공하고, 부족한 조각을 다운로드합니다.
이런 방식 덕분에 다운로드 속도가 빨라지고, 서버 비용이 절감됩니다.
P2P 네트워크의 종류
P2P 네트워크는 중앙 서버 의존도에 따라 크게 3가지 유형으로 나뉩니다.
1. 중앙 집중형 P2P (Centralized P2P)
중앙 서버가 피어들을 관리하고, 파일 목록을 제공합니다(과거의 프루나가 이 종류에 해당합니다).
검색 속도가 빠르고 관리가 쉽다는 장점이 있으나, 서버가 중단되면 네트워크 전체가 마비되는 단점이 있습니다.
2. 분산 하이브리드형 P2P (Hybrid P2P)
중앙 서버는 검색 기능만 담당하고, 파일 공유는 피어들끼리 직접 수행합니다.(eDonkey가 이 종류에 해당합니다).
중앙 서버 부담이 적어지고 네트워크가 안정적인 장점이 있으나, 서버가 없어지면 검색이 어렵다는 단점이 있습니다.
3. 완전 분산형 P2P (Pure P2P)
중앙 서버 없이 DHT(분산 해시 테이블) 기술을 사용해 피어들끼리 직접 검색하고 공유가 가능합니다.(현재의 토렌트가 이 종류에 해당합니다).
서버가 필요 없어 네트워크를 차단하기 어려우나, 초기 피어 연결이 어려울 수 있다는 단점이 있습니다.
사용자들간의 네트워크가 구축되어 서로 공유하는것, 어디서 많이 들어본 방식입니다.
추가로 탈 중앙화 P2P(Decentralized P2P)방식이 존재하는데, 이것이 바로 블록체인&암호화폐의 방식입니다.
중앙 기관 없이 사용자 간 거래가 가능하며, 거래 내역은 분산 원장(블록체인)에 기록됩니다.
(블록체인에 대해 간단하게 알아보기 →)
2. 토렌트(Torrent)
: 토렌트(Torrent)서비스는 일반적인 HTTP/FTP 다운로드와는 다르게, 여러 사용자(피어)들이 파일의 조각을 서로 공유하며 빠르고 효율적으로 전송할 수 있도록 설계되어있는 서비스입니다.

토렌트 네트워크의 주요 개념
트래커(Tracker)
토렌트 클라이언트가 피어들의 목록을 얻는 중앙 서버 역할을 합니다.
트래커 없이 작동하는 방식(마그넷 링크 기반)도 있으며, 이를 DHT(Distributed Hash Table)기반의 분산 네트워크라고 합니다.
피어(Peer)
파일을 다운로드하거나 업로드하는 모든 사용자를 의미합니다. 같은 파일을 요청한 사용자들끼리 데이터를 공유합니다.
시드(Seed)
파일을 100% 다 가지고 있으며, 다른 피어들에게 파일을 업로드하는 사용자를 의미합니다. 시드가 많을수록 다운로드 속도가 빨라집니다.
리치(Peer, Leech)
파일을 다운로드하면서 일부만 업로드하는 사용자. 업로드 없이 다운로드만 할 경우 네트워크에 기여하지 않는다고 해서 리처(Leech, 거머리)라고 불립니다.
DHT(Distributed Hash Table)
중앙 트래커 없이 피어 간 직접 연결을 통해 정보를 공유하는 기술을 의미합니다. 마그넷 링크 방식에서 많이 사용됩니다.
동작 원리
1. 토렌트 파일(.torrent) 또는 마그넷 링크(.magnet) 획득
토렌트를 사용하려면 먼저 토렌트 파일을 다운로드하거나 마그넷 링크를 얻어야 합니다.
.torrent 파일은 특정 파일의 조각 정보와 트래커(Tracker) 서버의 주소 등을 포함합니다.
마그넷 링크는 트래커 없이도 P2P 네트워크에서 파일을 찾을 수 있도록 해줍니다.
2. 토렌트 클라이언트(예: uTorrent 등)가 메타데이터 분석
.torrent 파일 또는 마그넷 링크를 이용해 토렌트 클라이언트가 해당 파일을 구성하는 조각(piece)정보를 분석합니다.
트래커 서버에 접속해 같은 파일을 공유하는 피어(Peer) 정보를 얻습니다.
3. P2P 네트워크에서 파일 조각 다운로드
파일이 여러 조각으로 나뉘어있어, 각각의 조각을 다른 피어들에게서 병렬적으로 다운로드합니다.
다운로드 속도는 시드(Seed, 완전한 파일을 가진 사용자)와 피어(Peer, 일부 조각을 가진 사용자)의 수에 따라 달라집니다.
4. 파일 조각을 완성하고 시딩(Seeding) 시작
모든 조각을 받으면 파일이 완성되고, 이제 다른 사용자에게 해당 조각을 제공(업로드)하는 시더(Seeder)가 됩니다.
3. P2P네트워크와 HTTP/FTP의 차이점
| 비교 항목 | 토렌트 (P2P) | HTTP/FTP (서버 기반) |
| 데이터 소스 | 여러 사용자가 공유 | 단일 서버에서 다운로드 |
| 속도 | 시드가 많을수록 빠름 | 서버 부하에 따라 변동 |
| 다운로드 방식 | 파일 조각을 여러 곳에서 병렬 다운로드 | 한 번에 한 서버에서 다운로드 |
| 안정성 | 일부 조각이 손상되더라도 복구 가능 | 서버 오류 시 다운로드 중단 |
| 중앙 서버 필요 여부 | 필요 없음(트래커 또는 DHT 사용) | 필요함 |
4. 트래커(Tracker)? DHT?
P2P 네트워크에서 파일을 공유할 때, '다른 사용자가 이 파일을 가지고 있는지 어떻게 찾을까?' 라는 의문점이 생깁니다.
이 문제를 해결하는 방식이 트래커(Tracker)와 DHT(Distributed Hash Table)입니다.
트래커(Tracker)란 ?
P2P 네트워크에서 파일을 공유하는 사용자의 목록을 관리하는 서버입니다.
사용자가 특정 파일을 다운로드하려고 하면, 트래커가 해당 파일을 가지고 있는 사용자(시드, 피어) 목록을 알려줍니다.
완전 분산형 P2P에서는 '서버'라는 말이 등장하지 않습니다. 이 방식은 주로 중앙 집중형 방식에서 사용되며, BitTorrent의 초창기 방식입니다.
트래커의 동작 방식
사용자가 .torrent 파일을 열면, 클라이언트는 트래커 서버에 접속해, 해당 파일을 공유하는 피어(사용자)목록을 사용자에게 제공하고, 클라이언트는 이 피어 목록을 바탕으로 여러 사용자에게 파일 조각을 요청합니다.
다운로드가 진행되면서, 클라이언트는 자신의 정보를 트래커에 다시 업데이트해 새로운 사용자가 접근할 수 있도록 합니다.
DHT(Distributed Hash Table)이란 ?
중앙 서버 없이 피어들끼리 직접 정보를 공유하는 방식입니다.
사용자가 파일을 다운로드하려고 하면, DHT 네트워크에 "이 파일을 갖고 있는 사람을 찾습니다." 요청을 보내고, 네트워크에 연결된 다른 피어들이 분산된 해시 테이블(DHT)에서 해당 파일을 가진 사용자를 찾아 응답합니다.
그렇게 찾은 피어들과 직접 연결해 파일을 다운로드 합니다.
역시 다운로드를 완료하면 DHT 네트워크에 등록되어 다른 사용자들이 접근할 수 있도록 합니다.
서버의 유/무와 네트워크의 개념이 잘 와닿지 않습니다.
두 방식을 비유해보자면, 트래커 방식은 빌릴 수 있는 사람 목록을 관리하는 중앙 도서관에서 책을 찾는다고 이해할 수 있습니다.
DHT 방식은 도서관이 존재하지 않고, 친구 A에게 책 위치를 물어 (예: B랑 C가 반반씩 갖고있던데), B와 C로부터 책을 찾는다.
고 이해할 수 있을 것 같습니다.
5. DHT(Distributed Hash Table)
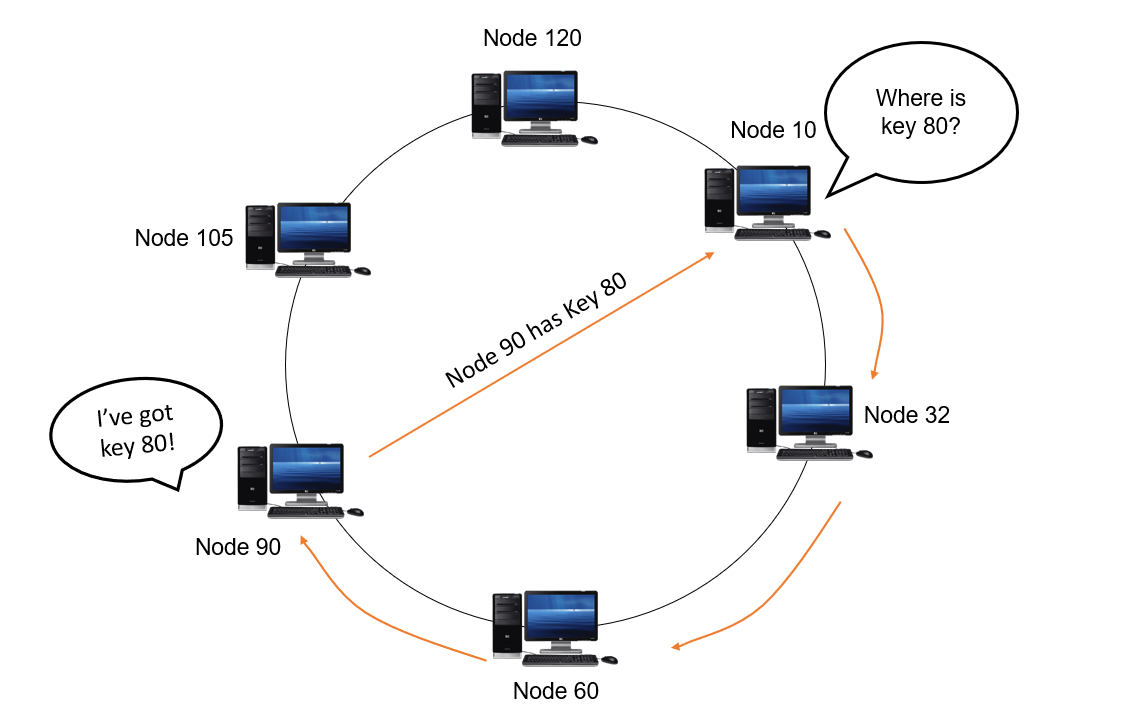
더 자세한 내용으로 들어가면
DHT는 해시기반 키-값 저장소로의 개념으로 이해할 수 있습니다.
"파일 해시 → 피어 목록"을 매핑해 저장하고 검색하는 시스템입니다.
토렌트에 적용된 예시로 방식을 설명해보겠습니다.
1. 각 파일(토렌트)은 고유한 해시 값(InfoHash)를 가집니다.
2. DHT 네트워크에 참여한(uTorrent 클라이언트를 가지는) 사용자(모든 피어)는 특정 해시 값 범위의 정보를 저장합니다.
3. 해시 값 기반의 검색을 수행하게되면, 해당 파일을 가지고 있는 피어를 찾게됩니다.
핵심 원리는 Kademila 알고리즘 방식을 따른다고 되어있습니다.
이 알고리즘이 갖는 특징(동작 방식)은
1. 각 피어(사용자)는 고유한 노드 ID(Node ID)를 갖는다.
2. 파일(토렌트)도 해시 값을 갖는다.
3. 노드 ID와 해시 값이 가까운 피어가 해당 파일의 정보를 저장한다.
DHT 검색과정을 예로들겠습니다.
1. 노드 DI 생성: DHT 네트워크에 참여하는 모든 피어들은 고유한 160비트 노드 ID를 갖는다고 설명했습니다.
예: 내 노드 ID: 0xA3B4C5D....
2. 파일 해시(InfoHash) 생성: 파일을 공유할 때, 해당 파일은 SHA-1 해시 알고리즘을 통해 InfoHash를 생성합니다.
예: text.txt 파일의 InfoHas: 0xF1A23B4...
3. DHT에 피어 정보를 저장: text.txt파일을 공유하는 사용자끼리는 DHT 네트워크 참여자로서 '해시 값이 자기 노드 ID에 가까운 다른 참여자를 저장' 합니다.
그래서, 다른 사용자가 text.txt파일을 공유받고자 하게되면, 네트워크에서 역으로 0xF1A23B4 파일 InfoHash와 가장 가까운 노드들을 역으로 찾아가면서 공유받게 되는것입니다.
'Network' 카테고리의 다른 글
| CDN(Content Delivery Network) 알아보기 (1) | 2025.02.10 |
|---|---|
| Wi-fi(와이파이) 어떻게 동작하는지 알아보기 (2) | 2025.01.31 |
| SSH에 대해 알아보기 (10) | 2025.01.16 |
| Http(HyperText Transfer Protocol) 알아보기 (5) | 2024.07.16 |