개발 알고리즘과 코딩테스트 문제풀이를 위해 가장 먼저 접하는 자료구조 중 하나인 배열입니다.
지금까지의 제 경험상으로 미루어보아, 프로젝트를 진행하면서 가장 많이 접하게 되고 직접 다루게 되는 자료구조 중 하나가 아닐까 싶습니다.
배열의 기본과 배열에 대해 알아보면서 들었던 궁금한 점에 대해 정리하고, 코딩테스트를 치룰 때 어떻게 사용해야 배열의 특성을 잘 사용할 수 있을지 적어보았습니다.
배열(Array)
: 동일한 자료형의 데이터를 연속된 메모리 공간에 저장하는 자료구조.
(단, 배열에도 종류가 있습니다. 그 중 하나가 연결된 리스트(LinkedList)인데요, 이 배열의 특징은 비연속적인 메모리에 동일한 자료형을 저장합니다. 다만, 각 저장된 메모리가 다음 노드를 가리키는 참조주소를 갖고 있어 논리적으로는 연속된 메모리 공간으로 표현합니다.)
- 배열이 갖는 특징은 다음과 같습니다.
- 순차적 메모리 배치: 연속된 공간에 저장되어 빠른 접근이 가능합니다.
- 인덱스(Index)기반 접근: 특정 위치의 데이터를 O(1)시간에 바로 가져올 수 있습니다.
- 고정된 크기: Java에서는 선언 시 크기가 고정됩니다.
배열은 메모리의 어디에 어떻게 생성되고 저장될까 ?

JVM에서 실행되는 Java 프로그램은 객체(Instance)와 배열(Array)를 Heap 영역에 저장합니다.
실제로, Java에서 배열을 생성할때 'new 배열종류' 생성자를 이용해 배열 객체를 생성합니다.
int[] arr = new int[5];
arr[0] = 10;
arr[1] = 15;이런식으로 정수 자료형 5개 만큼의 공간을 갖는 배열을 생성했을 때,
배열 자체는 힙 영역에 저장됩니다. 하지만 해당 배열의 주소를 참조하는 arr 변수는 스택 영역에 저장됩니다.
위의 예시를 살펴보면, 'new int[5]'로 배열이 갖는 공간을 제한해서 생성했습니다.
해당 공간보다 큰 데이터를 넣으려고 하면 ArrayIndexOutOfBoundException이 발생하게 됩니다.
배열 크기를 재조정하면서 써야한다면 동적 리스트(ArrayList)의 사용이 일반적입니다.
배열의 종류에는 어떤 것들이 있나 ?
위 내용을 보면 동적 리스트(ArrayList)나 연결된 리스트(LinkedList)등의 단어가 등장합니다.
어떤 종류가 있고 어떤 특징을 가지는지 알아봅니다.
1. 기본 배열(Array) - 정적 배열(Static Array)
- 크기 고정: 선언 시 크기를 지정합니다.
- 연속된 메모리 공간: 빠른 인덱스 접근(O(1))이 가능합니다.
- 삽입/삭제 비효율적: 중간에 요소를 추가/삭제하는 경우 앞 뒤의 모든 요소를 이동시켜야 합니다.(O(N))
2. 동적 배열(Dynamic Array, ArrayList)
- 크기 자동 조절: 배열이 꽉 차면 2배 크기로 확장합니다(Doubling Strategy)
- 배열 기반: 빠른 인덱스 접근(O(1))이 가능합니다.
- 삽입/삭제: 중간 삽입/삭제가 기본 배열과 마찬가지로 느려질 수 있습니다.(O(N))
3. 연결 리스트 기반 배열(LinkedList)
- 비연속적으로 메모리를 사용: 각 노드가 값과 다음 노드의 참조(포인터)를 가집니다.
- 인덱스 접근 느림: 처음부터 순차탐색해 원하는 인덱스에 접근합니다.(O(N))
- 삽입/삭제: 포인터만 수정하면 되므로 중간 삽입/삭제가 빠릅니다. (O(1))
4. 다차원 배열(Multidimensional Array)
- 2차원 이상의 배열: 표 형태의 데이터를 다룰때 유용합니다.
- 연속된 메모리: 2D는 배열의 배열 형태를 의미합니다.
- 인덱스 접근: 인덱스를 통해 빠른 접근이 가능합니다.(O(1))
| 구분 | 기본 배열(Array) | 동적 배열(ArrayList) | 연결 리스트(LinkedList) | 다차원 배열(Multidimensional Array) |
| 메모리 구조 | 연속된 메모리 | 연속된 메모리 | 비연속 메모리(노드 + 포인터) | 연속된 메모리(배열의 배열) |
| 크기 조절 | 고정 | 자동 조절 | 동적(노드 연결) | 고정(행, 열 지정) |
| 접근 속도 | O(1) | O(1) | O(n) (순차 탐색) | O(1) |
| 삽입/삭제 속도 | O(N) | O(N) | O(1) (중간 삽입) | O(n) (중간 삽입) |
| 메모리 효율성 | 높음 | 중간 | 낮음(포인터 추가 필요) | 중간(다차원 구조) |
| 특징 | 빠른 접근, 크기 고정 | 크기 유연성, 쉬운 사용 | 삽입/삭제 빠름, 탐색 느림 | 표 형태 데이터에 적함 |
이런 특성때문에, 고정 크기 데이터와 빠른 접근이 필요할 때는 기본 배열, 크기가 유연하면서 사용 편리성이 필요할 때는 ArrayList 등 개발자 필요에 따라 적절한 리스트를 사용하는 것이 좋습니다.
빠른 접근, 크기 자동 조절 등의 장점이 어느정도 차이를 발생시킬까 ?
앞서 소개한 리스트들의 특성이 유의미한 차이를 발생시키려면 어느정도의 데이터량 혹은 메모리크기가 필요할까요?
ArrayList는 모든 리스트들의 중간쯤되는 성능과 편리성으로 코드테스트를 진행하는데 가장 많이 사용되는 리스트라고 합니다.
그런데, 문제의 테스트케이스에 따라 극한의 데이터량이 인풋이 되어 시간초과를 발생시키는 경우가 있습니다.
리스트별 성능 차이가 실제로 언제 유의미해지는지를 한번 생각해봅니다.
성능 차이를 유발하는 주요 원인은 아래 네가지로 생각해볼 수 있습니다.
- 데이터 크기: 데이터가 많아질 수록 시간 복잡도와 공간 복잡도의 차이가 누적됩니다.
- 연산 횟수(반복성): 동일 연산이 반복되면 미세한 성능 차이가 크게 누적됩니다.
- 연산 종류(삽입/삭제/탐색): 자료구조별 특성에 따라 특정 연산의 속도가 큰 차이를 보입니다.
- 메모리 캐싱 효과: 배열 기잔 자료구조는 캐시 효율이 좋아 속도 차이가 크게 나타납니다.
아래는 간단하게 백만개의 데이터를 다룬다고 가정하고 삽입, 중간 접근 시간을 재어본 코드입니다.
package algorithms.boj.array;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
public class ListPerformanceTest{
public static void main(String[] args) {
// 테스트할 데이터 크기를 백만개로 선언
int dataSize = 1000000;
int middleIndex = dataSize / 2;
// ArrayList의 삽입/중간 접근 시간을 테스트합니다.
List<Integer> arrayList = new ArrayList<>();
long start = System.nanoTime();
for(int i=0; i<dataSize; i++){
arrayList.add(i);
}
long end = System.nanoTime();
System.out.println("ArrayList 삽입 시간: " + (end - start) / 1000000.0 + "ms");
start = System.nanoTime();
arrayList.get(dataSize / 2);
end = System.nanoTime();
System.out.println("ArrayList 중간 접근 시간: " + (end - start) / 1000000.0 + "ms");
// LinkedList의 삽입/중간 접근 시간을 테스트합니다.
List<Integer> linkedList = new LinkedList<>();
start = System.nanoTime();
for(int i=0; i<dataSize; i++){
linkedList.add(i);
}
end = System.nanoTime();
System.out.println("LinkedList 삽입 시간: " + (end - start) / 1000000.0 + "ms");
start = System.nanoTime();
linkedList.get(dataSize / 2);
end = System.nanoTime();
System.out.println("LinkedList 중간 접근 시간: " + (end - start) / 1000000.0 + "ms");
// ArrayList의 중간 삽입/삭제 시간을 테스트합니다.
start = System.nanoTime();
arrayList.add(middleIndex, 99999);
arrayList.remove(middleIndex);
end = System.nanoTime();
System.out.println("ArrayList 중간 삽입/삭제 시간: " + (end - start) / 1000000.0 + "ms");
// LinkedList의 중간 삽입/삭제 시간을 테스트합니다.
start = System.nanoTime();
linkedList.add(middleIndex, 99999); //⭐
linkedList.remove(middleIndex);
end = System.nanoTime();
System.out.println("LinkedList 중간 삽입/삭제 시간: " + (end - start) / 1000000.0 + "ms");
}
}
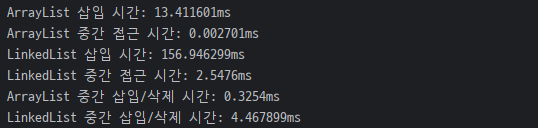
이상하게도 ArrayList의 중간 삽입/삭제가 LinkedList의 중간 삽입/삭제보다 빨랐습니다.
왜 이런 결과가 나왔을까요 ?
⭐이 포함된 주석의 라인을 살펴보시면,
linkedlist.add(index, value) 라인이 작성되어있습니다.
그런데 이 구문은 앞의 정리와 달리 시간복잡도가 O(n)입니다.
중간 삽입을 위해 get(index)를 실행해야 하는데, 이 작업이 O(n)번 수행되므로 중간 위치를 찾는 데에서 시간을 잡아먹기 때문입니다.
즉 LinkedList의 장점을 활용하기 위해선 'Node 객체'나 'Iterator'를 이용해 포인터로 바로 접근해야 합니다.
// 개선된 LinkedList의 중간 삽입/삭제 시간 테스트 입니다.
start = System.nanoTime();
ListIterator<Integer> iterator = linkedList.listIterator(middleIndex);
iterator.add(99999);
iterator.previous();
iterator.remove();
end = System.nanoTime();
System.out.println("개선된 LinkedList의 중간 삽입/삭제 시간: " + (end - start) / 1000000.0 + "ms");이렇게 코드를 추가하면 LinkedList가 생각했던대로 ArrayList보다 빠른 작업시간을 보일까요 ?

아이러니하게도, 작업시간은 여전히 LinkedList가 느립니다.
사실은, iterator가 해당 인덱스에 접근하는 것 또한 O(n)의 시간이 필요하기때문에 결과는 달라지지 않습니다.
LinkedList가 중간 삽입/삭제에 빠른 것은 해당 iterator가 고정된 상태로 삽입/삭제를 반복할 때에 해당됩니다.
(사실 이처럼 '인덱스 접근 → 삽입 → 삭제'의 반복에서 속도향상이 필요한경우 Deque(양방향 큐)를 사용한다고 합니다.)
(큐 알아보기 →)
int iterations = 100; // 반복 횟수
// ArrayList 반복 중간 삽입/삭제
List<Integer> arrayList = new ArrayList<>();
for (int i = 0; i < dataSize; i++) arrayList.add(i);
long start = System.nanoTime();
for (int i = 0; i < iterations; i++) {
arrayList.add(middleIndex, 99999);
arrayList.remove(middleIndex);
}
long end = System.nanoTime();
System.out.println("ArrayList 반복 중간 삽입/삭제 시간: " + (end - start) / 1_000_000.0 + " ms");
// LinkedList 반복 중간 삽입/삭제 (ListIterator 사용)
List<Integer> linkedList = new LinkedList<>();
for (int i = 0; i < dataSize; i++) linkedList.add(i);
start = System.nanoTime();
ListIterator<Integer> iterator = linkedList.listIterator(middleIndex);
for (int i = 0; i < iterations; i++) {
iterator.add(99999);
iterator.previous();
iterator.remove();
}
end = System.nanoTime();
System.out.println("LinkedList 반복 중간 삽입/삭제 시간: " + (end - start) / 1_000_000.0 + " ms");
그래서 위와 같이 작성해 코드를 테스트해야 원하는 결과를 받아볼 수 있습니다.
배열의 크기에 따라서도 어떤 차이가 있나 ?
웹개발 프로젝트로 예시를 들어보겠습니다.
게시판의 게시글을 응답할 때, 보통 페이지당 10개로 고정된 게시글을 응답한다고 가정합니다.
이때 응답되는 리스트의 형태를
Board[] boardList = new Board[10]; 으로 지정하는것과
List<Board> boardList = new ArrayList<>(); 로 동적 배열을 사용하는 것이 어떤 차이가 있을까요 ?
라고 스스로 의문을 던졌지만, 생각할 필요가 없었습니다..
각 배열들을 저렇게 저장하고 그 뒤에 가공한다면 배열 특성에 따른 차이가 발생하겠지만, 응답을 위해 단순 저장할 용도로는 두가지가 똑같지 않나 싶었기 때문입니다.
하지만, List<T>가 더 편할 것이라고 생각되는것이, 당장 프로젝트에서 사용해본 JPA나 관련 하위 메서드, Pagination 객체들을 사용해보면 반환타입이 List<T>인 경우가 많았기 때문에, 반환받은 배열을 new Board[10] 과 같은 형태로 재가공 하기보다 애초에 List<T>로 받아 응답할 생각을 하는것이 더 편할 것 같습니다.
(이 외에 Spring MVC 표준 직렬화도 List<T>타입에 더 최적화 되어있다고 하고, Java 컬렉션 표준도 List<T>타입을 사용하므로 여러모로 List<T>의 사용이 더 보편적일 것이라고 생각합니다.)
정리, 알고리즘 문제풀이를 위해
- 삽입/삭제보다 검색/정렬 위주로 문제가 나오는 배열관련 코딩테스트 문제를 풀 때에는, 빠른 접근과 무난한 성능을 제공하는 ArrayList가 가장 안전한 기본 선택지일 것입니다.
- 반복자(Iterator)가 유지된 상태에서 삽입/삭제가 반복되는 경우는 LinkedList가 유리한 선택지일 것이지만, 그런 상황은 드물 것 같습니다.
- 입력 데이터가 수백만 개 이상이고, 크기가 고정적인 경우 ?
ArrayList는 크기 확장(ensureCapacity())시 복사비용이 발생하므로, 고정된 크기의 작업이면 Array를 사용하는게 나을 것 같습니다. - 메모리사용량이 중요한 경우 ?
ArrayList는 size, capacity, modCount 등 추가적인 메타데이터를 저장하므로 Array보다 약간의 메모리 오버헤드가 발생할 수 있습니다.
추가 팁 !
배열의 인덱스는 일반적으로 '몇 번째 데이터인지' 나타내는 역할을 하지만, 상황에 따라 인덱스에 해싱개념을 적용해 단순한 위치가 아니라 특정한 의미를 지닌 값으로 활용하면 문제를 더 쉽게 해결할 수 있습니다.
강의 강좌를 보다보면 이를 '카운팅 배열' 이라고 표현하는 경우도 있습니다.
- A[1]의 의미
- 몇 번째 데이터인지 순서를 의미하는 경우 → 첫 번째 데이터를 저장합니다.
- 숫자값으로 의미를 부여한 경우 → 1이라는 값이 몇 개 있는지를 저장합니다.
2번방식으로 활용해 숫자값으로 의미를 부여하는 경우 유리한 상황을 가정해봅니다.
1000보다 작은 자연수 10,000,000개를 1초안에 정렬해야 하는 상황이라고 가정합니다.
일반적인 방법으로는 1초 안에 정렬하기 어렵지만 인덱스르 값 자체로 활용하면 계수 정렬과 같은 방식으로 제한 시간 내에 정렬할 수 있습니다.
'Data Structure > Basic' 카테고리의 다른 글
| 시간 복잡도와 공간 복잡도 (1) | 2025.03.04 |
|---|